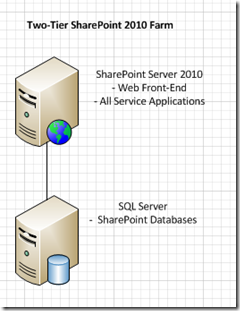
Many small to medium-sized organizations start using SharePoint in a “two-tier” server farm topology. The two tiers consist of:
- Tier 1 – SharePoint Server with all web page serving and all Service Applications running on it
- Tier 2 – A SQL Server to store the SharePoint databases – the SQL Server could be dedicated to the farm or it might be shared with other non-SharePoint applications.
This farm topology can frequently support companies with hundreds of employees. Of course, it depends a lot on the specifications of the hardware, but with late-model quad-core Xeons running on the two servers and 8 – 16 GBs of RAM on each one with RAID built with 15k RPM SAS drives in the SQL Server, this configuration with SharePoint Server 2010 can perform very well in many organizations that have less than 1000 users.
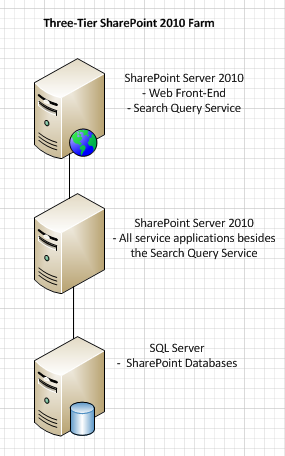
At some point, an organization that started with this two-tier topology may want to scale out to the next level which is a three-tier topology. The three tiers would be:
- Tier 1 – SharePoint Server dedicated as a Web Front-End (WFE) with only the web application(s) and the search query service running on it
- Tier 2 – SharePoint Server dedicated as an Application Server with all of the other service applications running on it, but no web applications or query service
- Tier 3 – SQL Server for the databases
Visually, this topology looks like this:
1. Scaling Out SharePoint 2010 Farm From 2-Tier to 3-Tier
Many small to medium-sized organizations start using SharePoint in a “two-tier” server farm topology.
The 2-Tiers consist of the main components:
1. Tier 1 – SharePoint Server with all Web page serving and all Service Applications running on it.
2. Tier 2 – A SQL Server to store the SharePoint databases – the SQL Server could be dedicated to the farm or it might be shared with other non-SharePoint applications.
This configuration with SharePoint Server 2010 can perform very well in many organizations that have less than 1000 users
At some point, Organizations that started with two-tier topology need to scale up to 3-Tier depending on the business need/requirement.
3-Tier components are broadly classified into the following segments:
1. Tier 1 – SharePoint Server dedicated for Web Front-End (WFE) with only Web application(s) and Search Query running on it.
2. Tier 2 – SharePoint Server dedicated for Application Server (App server) with all of the other service applications running excluding Web Applications and Query Service.
3. Tier 3 – SQL Server for the Content DB/Search DB etc.
There are many different reasons why a company might want to scale out to 3-Tiers. Some kind of performance improvement is frequently what drives it. However, it may not be the obvious one of desiring better page serving times for the end users. For instance, frequently companies do this to move the search crawling and index building process to a different server that is more tuned for its unique resource requirements and can do a more efficient job of crawling and indexing the company’s content. Perhaps in the two-tier approach their crawl\index component can’t get enough hardware resources to crawl through all of the content on a timely basis.
Services on Server page will have all of the service applications that run on the SharePoint 2010 server in a two-tier farm when you install SharePoint Server 2010 Enterprise edition and run the out-of-the-box configure Your SharePoint Farm Wizard and choose to provision all service applications.
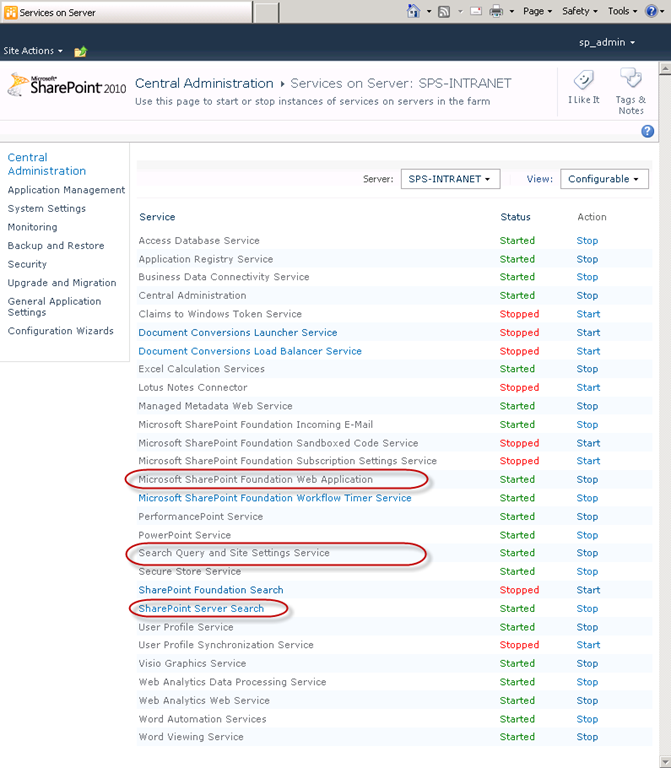
Our goal is to add a third server to the SharePoint 2010 farm and have it take over running all of the service applications in the list Services on Server, with the exception of below three.
· Microsoft SharePoint Foundation Web Application
· Search Query and Site Settings Service
· SharePoint Server Search
These three are the ones that are necessary for the original server to function as a dedicated WFE with query processing.
The Search Query and Site Settings Service and some of its associated functionality in the SharePoint Server Search Service are technically not required on a WFE, but it is the best place to put them. The reason is that this is the process that takes the user’s search query and looks it up in the indexes. The indexes are files that the query processor needs local access to and are stored on the file system of the server(s) that is running the query service, not in SQL Server.
So, for best performance it is recommended to run the Search Query and Site Settings Service on the WFEs that are serving the pages. The crawling and index process is a separate process whose job it is to build the indexes and push them up to the query servers.
The Search Topology configuration settings in SharePoint 2010 dictate what functionality of the SharePoint Server Search Service runs on what server in the farm. So, while the SharePoint Server Search Service needs to run on both the WFE and the Application Server, it will be possible break out the functionality that it performs on each. We will want it to perform query-related functionality on the WFE and crawling/indexing functionality on the Application Server.
Take a fresh physical or virtual server that has Windows Server 2008 (R1 or R2) running on it, and install all the same SharePoint Server 2010 software on it that is installed on the existing SharePoint 2010 server in your existing farm. That includes the full RTM Enterprise edition, whatever patches have been applied in your farm since RTM, and any other separate products that have been installed on your existing server such as the Office 2010 Web Applications and its patches.
Install all RTM software and all patches that have previously been applied to the farm BEFORE running the SharePoint 2010 Products Configuration Wizard from the new server’s Start menu. This means that you will want to respond NO to the prompt to automatically run the wizard until you have installed all software packages on the new server. This will save you from having to run the wizard multiple times. Run it once – after you have installed all software and patches on the new server.
When you do run the SharePoint 2010 Products Configuration Wizard, you will run it on the new server that will be your application server.
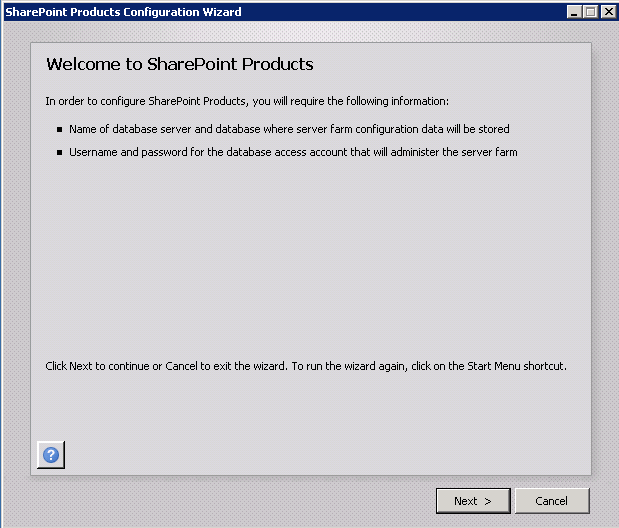
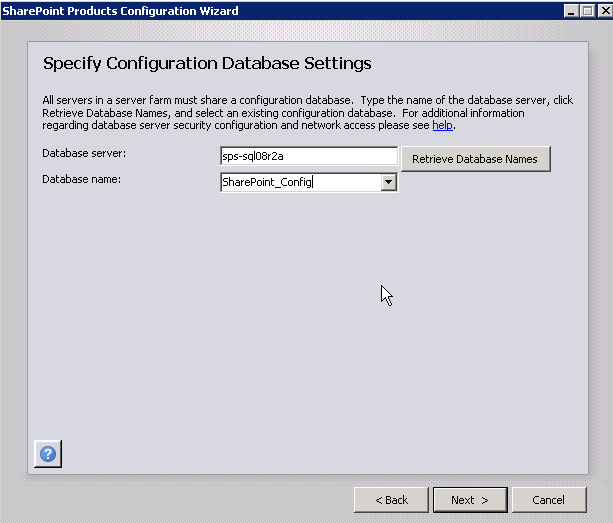
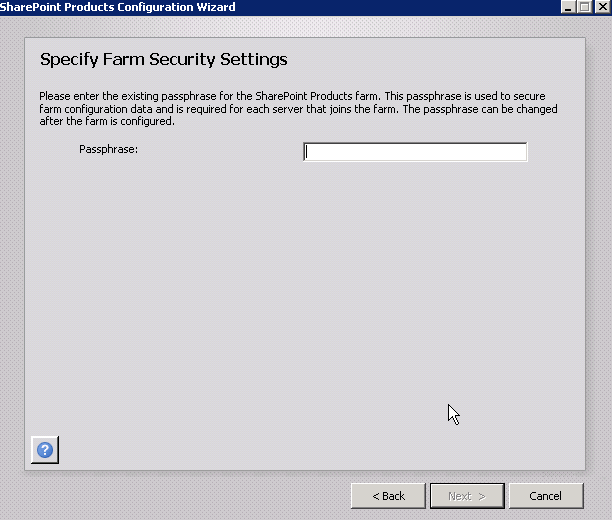
A screen in the wizard asks you for the Farm passphrase. This is a special password you created when you originally created the farm. You have to enter it here in order to join this server to the farm.
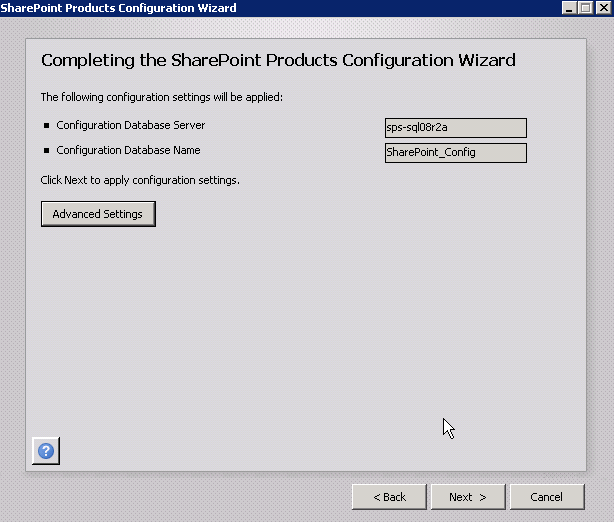
Now the server has been joined to the farm and is a full-fledged farm member. But, the Configure Your SharePoint Farm Wizard in Central Administration needs to run to add the service applications that exist in the farm to this new server. So, it automatically fires up your browser and asks you to run the Farm Configuration Wizard.
Verify that the new server is showing up as a member of the farm with a healthy status. To do that go to Central Administration > System Settings > Manage Servers In This Farm and find the new server and verify that it has a “No action required” status. This is now a three-tier SharePoint 2010 farm.
Next step is to ensure that the three-tier farm has only the web page serving and query processing services running on the WFE and all of the other service applications running only on the Application Server.
(Note: the farm will work and be fully functional if you stop here. You will have the same Service Applications running on multiple servers and SharePoint 2010 will automatically use this topology as a load balancing technique for the Service Applications. There may be some environments where this is desired. But, most organizations will want to separate the web-serving services and the application-serving services to provide a better balance for the farm as a whole as opposed to just load balancing the Service Applications.)
The Web Front-End should run these (and only these) services:
1. Microsoft SharePoint Foundation Web Application (this is what turns IIS into a SharePoint “page-serving” machine)
2. Search Query and Site Settings Service (the process that takes the user’s query string and looks it up in the index)
3. SharePoint Server Search Service (but just the functionality that is necessary for the query processor)
4. Central Administration (assuming it is not moved it to the Application Server)
The Application Server should run these (and only these) services:
1. Access Database Service
2. Application Registry Service
3. Business Data Connectivity Service
4. Excel Calculation Services
5. Managed Metadata Web Service
6. Microsoft SharePoint Foundation Incoming E-mail
7. Microsoft SharePoint Foundation Workflow Timer Service
8. PerformancePoint Service
9. Secure Store Service
10. SharePoint Server Search (but just the scheduled content crawling and indexing building functionality)
11. User Profile Service
12. Visio Graphics Service
13. Web Analytics Data Processing Service
14. Web Analytics Web Service
15. Word Automation Services
16. Word Viewing Service
(Important Note: Step 1 above is really the only step in the process that can be done during normal working hours. Everything else has the potential to impact the availability of the system to the users. Of course, it is highly recommended to have solid backups in place before starting Step 2.)
For the most part, the re-configuration of the services involves stopping a lot of services on the WFE server (using the Services on Server page in Central Admin) and verifying that they are running on the new server (which they probably are because the Configure Your SharePoint Farm wizard started them up when you ran it in Step 2). Then, you will want to make one last pass over the list of services running on the Application Server and make sure that the Microsoft SharePoint Foundation Web Application Service and the Search Query and Site Settings are not running on it.
Adjusting the Search Application Topology
The exception to the statements of the previous paragraph is the search-related services: SharePoint Server Search Service and Search Query and Site Settings Service. Search is complicated enough that it has its own topology configuration settings. We need to use this capability to place the query functionality of the SharePoint Server Search Service on the WFE and to place the crawling\indexing functionality of the service on the Application Server.
Since this is a little more complicated than the other Service Applications, this must be done first.
Navigate to the Search Administration home page in Central Administration. Scroll down to the bottom of the page until you see the section titled Search Application Topology:
This part of the page shows you what servers the following four components of the Search service are running on:
· Search Administration component
· Crawling component (this is the crawling engine that crawls your content and builds full-text indexes from it)
· Database component (as the crawling engine crawls through the content, it stores the full-text indexes in SQL Server. It also compiles the full-text indexes into special non-SQL files that can be propagated up to the WFE)
· Query component (this is the component that receives the user’s query and looks up the results in the special files that have been propagated to the hard drive of the WFE)
The Server Name column shows that the Search Administration, Crawl, and Query components are currently running on the existing server. The search-related databases are running on the SQL Server.
You want to do the following:
1. Move the Search Administration component to the new Application Server
2. Move the Crawl component to the new Application Server
3. Leave the Database component running on the SQL Server
4. Leave the Query component running on the WFE
To accomplish this, click on the Modify button to go to the Topology for Search Service Application page
By hovering your mouse over the component lines, you can bring up a drop down menu and select Edit Properties for the components you want to move to the new server.
Do this now for the Search Administration component.
Now do it the same way for the Crawl component. Once you have changed the server assignments for these two components, you need to kick of the actual transfer of responsibilities by clicking on Apply Topology Changes.
When it is finished, you will be returned to the Search Administration home page and you should see that the components have been transferred as directed and all of the search-related servers should have a status of “Online”:
Transferring the remaining Service Applications
All that is left is to use the Services on Server page in Central Administration to make sure the list of services running on each server matches your master list from above:
You want the Web Front-End to run these (and only these) services:
1. Microsoft SharePoint Foundation Web Application (this is what turns IIS into a SharePoint page-serving machine)
2. Search Query and Site Settings Service (the process that takes the user’s query string and looks it up in the index)
3. SharePoint Server Search Service (only the functionality that is necessary for the query processor)
4. Central Administration.
You want the Application Server to run these (and only these) services:
1. Access Database Service
2. Application Registry Service
3. Business Data Connectivity Service
4. Excel Calculation Services
5. Managed Metadata Web Service
6. Microsoft SharePoint Foundation Incoming E-mail
7. Microsoft SharePoint Foundation Workflow Timer Service
8. PerformancePoint Service
9. Secure Store Service
10. SharePoint Server Search (only the scheduled content crawling and indexing building functionality)
11. User Profile Service
12. Visio Graphics Service
13. Web Analytics Data Processing Service
14. Web Analytics Web Service
15. Word Automation Services
16. Word Viewing Service
To do this, you use the Server drop-down control to select the server you want to adjust, and then use the Start/Stop link in the Action column to turn on/off the services.
Below are the steps to for testing:
1. Browse to each of the SharePoint web applications and log in with your user account and make sure you can hit the home page of each of them.
2. In the opened sites, try to open up and edit a document in the browser using one of the Office 2010 Web Apps (Word, PowerPoint, Excel or OneNote).
3. Browse to your My Site and verify that everything is working normally.
4. Add a unique phrase to a test page somewhere in one of your Sites and then go run an incremental Search crawl from Central Administration. After the crawl completes, go back to your Site Collection and search for the phrase. Verify that it comes up in the results.
5. Run an incremental User Profile Synchronization from the User Profile Administration page. While it is running, logon to the desktop of the new Application Server, and find this program and run it: c:\program files\microsoft office servers\14.0\synchronization service\uishell\miisclient.exe. This is the Forefront Identity Management (FIM) client application that you can use to see the details of the AD synchronization process. Several jobs will be run by FIM. Verify that they all complete successfully with no error messages.
6. In Central Administration, go into Manage Service Applications and click on Managed Metadata Service and select Manage in the ribbon. Verify that the Term Store management interface loads and that you can add/change/delete a Term Set and some Terms.
7. Finally, reboot your WFE and Application Server. When they come back up, check your Windows System and Application event logs on those servers and verify that there are no SharePoint-related critical or warning events that you haven’t seen before you scaled out to three tiers.
8. Browse to your primary web application one final time.
There are many different reasons why a company might want to scale out to three-tiers from two. Some kind of performance improvement is frequently what drives it. However, it may not be the obvious one of desiring better page serving times for the end users. For instance, I frequently see companies do this to move the search crawling and index building process to a different server that is more tuned for its unique resource requirements and can do a more efficient job of crawling and indexing the company’s content. Perhaps in the two-tier approach their crawl\index component can’t get enough hardware resources to crawl through all of the content on a timely basis.
One more point. Many organizations will also choose to add a second WFE when they scale out to a three-tier farm. (I don’t show this in the diagram above). The second WFE will be configured exactly like the first one and some type of network load balancing (NLB) mechanism will be put in front of the WFEs to intelligently route user traffic to the two servers to balance out the load. In this scenario, the three-tier farm diagram above would be modified to add a second WFE and the total number of servers in the SharePoint farm would be four.
 Subscribe
Subscribe